你跟 AI 說了那麼多,它為什麼每次都失憶?
 Dr. J
Dr. J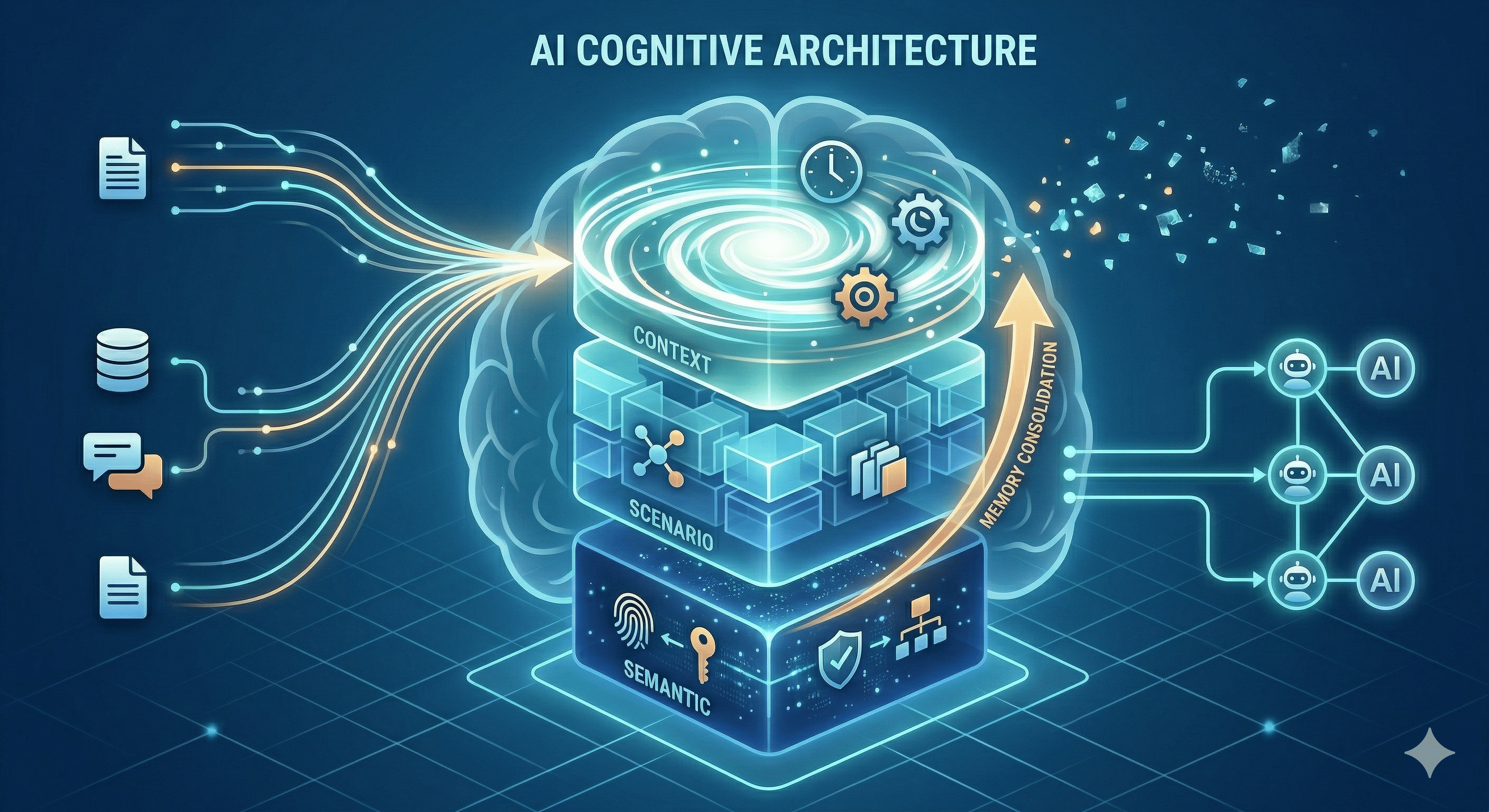
每次開 session,你先做的不是工作,是「準備工作」
你今天要推進一個功能,或者解一個 bug。你開了一個新的 AI session,準備請它幫你。
因為 LLM 本質是一個無狀態,所以導致一個問題:它什麼都不知道。
你要先解釋這是什麼專案、技術棧是什麼、這個功能的背景是什麼。相關資料在哪裡?需求在 Notion 或某個 Google Doc;上次討論這個問題的 AI 對話已經關掉,來龍去脈消失了;相關的程式碼在三個不同的資料夾;前幾天在 Slack 跟同事確認過的一個設計決策,現在要回去翻、複製貼上。然後把這些拼在一起,用幾段話解釋給 AI 聽。
前置作業花了二十分鐘。然後 AI 幫你做了那個本來五分鐘就能解決的事。
明天,同一個專案,新的 session,整個流程重來一遍。
這個問題的惱人之處不只是「AI 不記得我是誰」。更根本的是:每一次工作,都要重新把散落在各個地方的 context 收攏起來、餵給 AI,它才能真正幫上忙。 你的工作記憶分散在 Notion、GitHub、Slack、本地資料夾、上個 AI session——而每個新 session,AI 的起點永遠是白板。
這不是 AI 不夠聰明的問題。這是一個架構問題。
AI 記憶,是 2026 年最多人同時在解的問題
有趣的是,就在最近兩週,關於記憶的解決方案流行了起來:
Andrej Karpathy 發了一份 Gist。 這位前 Tesla AI 總監、OpenAI 創始成員,公開了他的「LLM Knowledge Base」架構:一個用結構化 Markdown 取代 RAG 的知識管理系統。
他的核心論點很簡單:RAG 是為了「context window 裝不下」而生的 workaround,現在 context window 夠大了,直接讀結構化文本比 embedding 檢索更精準、更可控。不需要向量資料庫,不需要 embedding pipeline,只需要 LLM + filesystem。
Milla Jovovich 推出了 MemPalace。 對,就是《惡靈古堡》的 Milla Jovovich。她跟工程師 Ben Sigman 合作,把古希臘的「記憶宮殿法」移植到 AI 記憶架構——用空間隱喻(Wing → Hall → Room → Drawer)來組織記憶,讓 AI 先導航再檢索,而不是在整個資料庫做暴力搜尋。48 小時內 GitHub 突破 23,000 stars。
Nous Research 發布了 Hermes Agent。 一個標榜「自我進化」的 AI agent runtime——它在幫你執行任務的過程中,自動把做過的事提煉成可重用的技能,越用越聰明。官網的 pitch 是:「住在你機器上、每天都在變聰明的智能體。」在開發者社群引發大量討論。
一個 AI 研究員、一個好萊塢演員、一個 AI 新創,在同一週各自提出了自己的答案。
這說明了什麼?「AI 失憶」不是 niche 問題——它是 2026 年每個認真使用 AI 的人都在被困擾的基礎設施級痛點。
他們三個看到的是同一個問題:AI 跑在你的任務上很強,但每次都從零開始。問題出在哪裡,他們各自給出了答案——但我認為都還沒抓到根本。
四條解法路線,各有一個致命缺口
問題不是 AI 的上下文窗口不夠大。
GPT-4o 有 128K tokens 的 context window。Claude 有 200K。Gemini 甚至號稱百萬。能塞的東西不少。問題在於:你塞什麼進去,以及誰來塞?
目前市場上的「AI 記憶」方案,大致分四條路線:
路線一:萃取摘要派(Mem0、Zep、ChatGPT Memory)
做法:LLM 從對話中抽取「事實」→ 存進向量資料庫 → 下次對話時用 embedding 搜出來塞進 context。
問題是,萃取本身就是有損壓縮。誰決定「什麼值得記」?LLM 自己。它會記住你喜歡喝咖啡,但忘記你上週做了一個關鍵的架構決策。這些記憶是一堆扁平的事實碎片,沒有層次,沒有優先級,也沒有「這條事實是在什麼情境下產生的」。
更根本的問題:這些記憶屬於平台。換一個工具,記憶就消失。你在 ChatGPT 累積的三個月 memory,搬不到 Claude。你在 Mem0 存的東西,離開 Mem0 就拿不到。
路線二:全存原文派(MemPalace)
做法:不萃取,對話原文全部存下來,用空間結構讓它可被導航和檢索。
這解決了「萃取有損」的問題,但帶來新問題:規模。當你的 drawers 超過 40,000 個,ChromaDB 開始 OOM。而且——同樣的根本問題——知識仍然綁定在特定系統裡。
路線三:Markdown-first 結構化(Karpathy LLM Wiki)
做法:人類丟原始素材進 raw/,LLM 主動編譯成結構化 Markdown wiki。查詢時 LLM 讀索引,定位相關頁面,直接推理。
這個方向最接近正確答案。Karpathy 看到了關鍵的東西:知識需要結構,不只是容量。但他的方案是為「外部知識庫」設計的——你蒐集的論文、文章、研究資料。它沒有處理一個更私人的問題:你跟 AI 的工作記憶要怎麼累積?
路線四:自我進化派(Hermes Agent)
做法:把 AI 做成長駐的 agent runtime。它在幫你執行任務的過程中,自動把解決方案提煉成可重用的技能,存在本地;下次遇到類似問題,直接呼叫。越用越聰明,不需要你手動整理。
這個思路很吸引人——讓系統的知識積累完全自動化,人不用介入。但它有一個根本的盲點:Hermes 的知識屬於 Hermes,不屬於你。
那些自動生成的技能存在 Hermes 的資料夾和資料庫裡,是 Hermes 這個 agent 的財產。你決定換用另一個工具?記憶不跟著走。Hermes 停止維護?知識消失。你想知道 AI 上週「學到了什麼」、能不能手動修正一個錯誤的技能?做不到——底層是隱性積累,不是透明的知識庫。
四條路線,四個不同的問題意識,但沒有一條真正解決的核心矛盾是:AI 記憶沒有分層,而且知識不是你的。
AI 只有工作記憶,缺了大腦最重要的兩層
你的大腦不是這樣運作的。
神經科學告訴我們,人類的記憶至少有三個層次:
- 工作記憶(prefrontal cortex):你現在正在處理的事——這個 bug、這段程式碼、這封 email。幾分鐘到幾小時。
- 情景記憶(hippocampus):你上週做了什麼、昨天跟誰開了會、那個 PR 為什麼被 reject。幾天到幾個月。
- 語意記憶 / 程序記憶(neocortex):你是誰、你的技術棧、你的思考風格、你合作的原則。幾年到永久。
每晚睡覺時,海馬迴會把白天的情景記憶「重播」並壓縮,有價值的部分逐漸固化到大腦皮層,成為你的長期知識。這個過程叫 memory consolidation——記憶固化。
現在看看 AI。它有工作記憶(context window),但完全沒有情景記憶和語意記憶的分層。每個 session 就是一個獨立的夢,醒來就忘。
Mem0 試圖用向量資料庫模擬記憶,但它把所有記憶都塞在同一層——你喜歡的咖啡口味、你正在趕的 deadline、你的架構偏好,全部是扁平的 key-value pair。沒有「這個記憶應該持續多久」,沒有「這個記憶屬於哪個層次」。
AI 記憶的問題,不是「記不住」,不是「記憶體不夠大」,而是「記憶沒有結構」。
優化的架構:三層記憶
如果我們從大腦的記憶分層出發,一個 AI 的 context infrastructure 至少需要:
-
永久層:「我是誰」
你的身份、偏好、決策原則、工作風格。這一層每個 session 都要被載入,像你的個性一樣穩定。 -
中期觀察層:「最近發生了什麼」
工作日誌、專案進度、最近學到的教訓。這些資訊有保質期,需要定期被壓縮或淘汰。 -
專案層:「我現在在做什麼」
特定任務的目標、現況、決策記錄。按需載入,任務結束就歸檔。
而且,這三層之間需要有流動——就像大腦的記憶固化:短期觀察中反覆出現的模式,應該被提煉成永久規則。
更關鍵的是:這個結構不應該綁定任何特定的 AI 工具。 Mem0 的記憶屬於 Mem0 的平台。MemPalace 的 palace 活在 MemPalace 的資料庫裡。Hermes 自動積累的技能是 Hermes instance 的財產。四條路線,有同一個死角:換工具,你重頭來。
正確的思路應該是:工具是消費者,你的知識系統才是主體。 Claude 可以讀你的知識,Cursor 可以讀,下一個你還沒聽過名字的 AI 工具也可以讀。記憶不能跟著工具走,但它可以跟著你走。
我正在解這個問題,這個系列是我的實驗紀錄
我按這個架構建了一套自己用的系統,目前還在早期驗證階段。
架構的方向我是確信的——知識分層、屬於自己、任何 AI 工具都能讀。
這個系列就是這個過程的公開紀錄。
下一篇,我會深入解釋:為什麼你的 AI 記憶不應該住在向量資料庫裡——以及一個真正屬於你的知識系統應該長什麼樣。
這是《真正的第二大腦》系列的第一篇。如果你也被 AI 的失憶問題困擾,歡迎追蹤這個系列。
Dr. J
喜歡這篇文章嗎?
訂閱電子報,不錯過最新內容!