好文分享 -〈深耕垂直軟體十年:我如何看待這波拋售〉
 Dr. J
Dr. J
點評:
這篇文章分析了軟體產品(尤其是 SaaS)傳統的 10 大護城河,以及 AI 出現對軟體的影響和展望。
對於近期我在規劃開發軟體產品與傳統大公司的軟體與系統競爭,以及未來開發軟體產品的趨勢(有了 AI 加入後),這篇文章給了我許多 insight,也和我感受到的趨勢大致相同。所以我將原文翻譯成繁體中文,並花了一些時間校對和編修,給有興趣的讀者可以更方便的閱讀。
未來我會再寫一篇我對於這 10 個護城河衝擊的觀點,以及面向正在開發軟體系統或是產品的工程師們,要怎麼去因應。
以下原文:
在過去幾週內,軟體與服務類股市值蒸發了將近 1 兆美元。
FactSet 從 200 億美元高點跌到不到 80 億。
S&P Global 在短短幾週內 下跌 30%。
Thomson Reuters 在一年內 市值幾乎腰斬。
由 140 家公司組成的 S&P 500 軟體與服務指數,今年以來下跌 20%。
上週,Anthropic 發布了 Claude 的 Cowork 產業專用插件。Cowork 是一個專為知識工作者打造的 AI Agent,可以自主處理複雜的研究、分析與文件工作流程。
華爾街稱這一切為「恐慌」。而我,在過去十年都在打造 垂直型 SaaS。
先是 Doctrine——如今歐洲最大的法律資訊平台(與 LexisNexis、Westlaw 競爭),接著是 Fintool——一個美國的 AI 股票研究平台,現在正與 Bloomberg、FactSet、S&P Global 正面競爭。
我打造過 現在正被 LLM 威脅的那種軟體,也正在打造 正在發動這場威脅的那種軟體。我站過這場顛覆的兩側。
這是我看到的現實:
LLM 正在系統性地拆解讓垂直軟體具有防禦力的護城河——但不是全部。結果不是毀滅,而是重新定義:
什麼樣的垂直軟體仍然有價值,以及它們配得上什麼樣的估值倍數。
這篇文章將討論:
- 讓垂直軟體具備防禦力的十道護城河,以及 LLM 對它們各自造成的影響
- 為什麼市場的拋售在結構上是合理的,但在時間點上被誇大了
- 真正的威脅是什麼(不是你以為的那個)
- 什麼將取代傳統垂直軟體
- 以及這個 5000 億美元以上的垂直軟體產業 接下來會發生什麼事
垂直軟體的十道護城河(以及 LLM 對它們做了什麼)
垂直軟體,是為特定產業打造的軟體。金融有 Bloomberg,法律有 LexisNexis,醫療有 Epic,營建有 Procore,生命科學有 Veeva...
這些公司有一個共同點:收費很高,而且客戶幾乎不會流失。
FactSet 每位使用者每年收費 1.5 萬美元以上。
Bloomberg Terminal 每席 2.5 萬美元。
LexisNexis 對律師事務所每月收取數千美元。
而留存率通常都在 95% 左右。
我認為,這背後有 十種不同的護城河。
LLM 正在攻擊其中一些,同時對另一些幾乎沒有影響。
搞清楚哪些會倒、哪些會撐住,是整場博弈的關鍵。

1. 學習成本極高的介面 → 被摧毀
Bloomberg Terminal 的使用者,花了多年學習鍵盤快捷鍵、功能代碼與操作邏輯。GP、FLDS、GIP、FA、BQ。這些不是直覺操作,而是一種「語言」。
一旦你能流利使用,改用其他平台就等於重新變成文盲。
我聽過無數次:「我們是 FactSet 派。」「我們整間事務所用 Lexis。」「我們是 Bloomberg 家族。」
這些話不是在談資料品質,而是在談肌肉記憶。人們花了十年學會一套工具,而這份投資是無法轉移的。
這是最被低估的護城河。知識工作者付費,是為了不要重學一套工作流程。
我在 Doctrine 親身經歷過這件事。我們有設計師團隊,還有一整支客戶成功團隊,專門負責教律師怎麼用介面。每一次 UI 調整都是專案:使用者研究、設計衝刺、分批上線、手把手教學。光是一個分面搜尋的改版,就能花上好幾週,因為律師已經對舊操作產生肌肉記憶。
介面不是功能;介面本身就是產品。
而在 Fintool,我們完全沒有 onboarding。沒有 CSM 教你怎麼用。使用者直接用自然語言輸入問題,然後得到答案。沒有要學的介面。
那整個成本中心——設計師、CSM、UI 變更管理——直接消失。Chat 介面吸收了所有這些結構。
LLM 把所有專有介面,壓縮成一個 Chat。
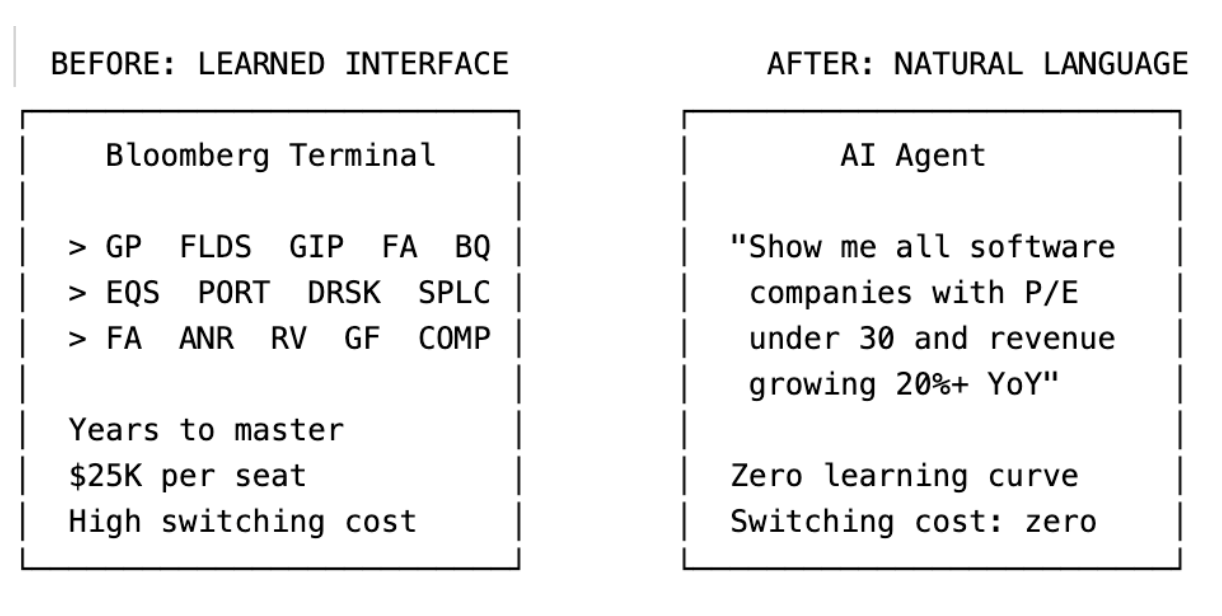
想像一位金融分析師今天在 Bloomberg Terminal 上的工作流程:
他進入股票篩選功能,用專用語法設定條件,匯出結果。切換到 DCF 模型工具,輸入假設,跑敏感度分析。匯出 Excel,製作簡報。
每一步都需要學習過的介面知識、每一步都在加深轉換成本。
現在換成 LLM agent:
「列出市值超過 10 億美元、本益比低於 30、年營收成長超過 20% 的軟體公司。對前五名建立 DCF 模型,並針對折現率與終值成長率做敏感度分析。」
三句話。沒有快捷鍵、沒有功能代碼、沒有導航。
使用者甚至不知道資料來自哪個供應商。也完全不在乎。
當介面變成自然語言對話,多年累積的肌肉記憶就變得一文不值。支撐每位人 2.5 萬美元年費的轉換成本消失了。
對許多垂直軟體公司而言,介面本身就是主要價值。
底層資料多半是授權的、公開的、或半商品化的。真正支撐高價的,是建在資料之上的工作流程。那個時代結束了。
2. 客製化工作流程與商業邏輯 → 化為烏有
垂直軟體承載著一個產業實際運作的方式。一個法律研究平台不只是存放案例法,它還編碼了引用網絡(citational networks)、Shepardize 信號、重點摘要分類,以及訴訟助理撰寫訴訟書狀的具體流程。
這些商業邏輯的建立花了多年時間,反映了與無數領域專家的對話經驗。當我打造 Doctrine 時,最困難的不是技術本身,而是理解律師實際的工作方式:他們如何研究案例法、如何起草文件、如何從案件接收到審判建立訴訟策略。將這種理解編碼進可運作的軟體,是垂直軟體有價值且可防禦的關鍵。
大型語言模型(LLM)則把這一切轉化成一個 Markdown 檔案。
這是最被低估的變化,也是我認為最具毀滅性的長期影響。
傳統垂直軟體將商業邏輯寫進程式碼中。成千上萬的 if/then 條件、驗證規則、合規檢查、審批流程……這些都是由多年經驗的工程師硬寫而成。這不只是一般工程師就能做到的,你需要既懂程式碼又了解領域的工程師,這種人才極為稀缺。修改這些商業邏輯需要開發週期、品質測試、部署。
舉我自己的經驗做例子:
在 Doctrine,我們建立了一個法律研究工作流程,幫助律師找到針對特定法律問題的相關案例。系統必須理解法律領域(民事、刑事、行政)、將問題解析成可搜尋概念、跨多個法院資料庫查詢、依相關性與權威性排序結果,並呈現正確的引用脈絡。這一切花了工程師與法律專家數年的努力。商業邏輯散布在成千上萬行 Python 程式碼、自訂排名算法和手調的相關性模型中,每次修改都需要工程衝刺、程式碼審查、測試與部署。
在 Fintool,我們有一個 DCF(折現現金流)估值技能,它告訴 LLM 代理如何做折現現金流分析:要收集哪些資料、如何按行業計算 WACC、哪些假設需要驗證、如何進行敏感度分析、何時加回股票報酬。這只是一個 Markdown 檔案。撰寫它花了一週時間,更新只需幾分鐘。一位做過 500 次 DCF 估值的投資組合經理,可以在不寫一行程式碼的情況下,把整套方法學編碼完成。

而且不只是速度:Markdown skill 有更為重要的面向。任何人都能讀懂、可審計、可按使用者自訂(我們的客戶也能自己寫 Skill),而且隨著底層模型進步,它會自動變得更好,而我們不需要碰一行程式碼。
商業邏輯正從專業工程師撰寫的程式碼,遷移到任何領域專家都能撰寫的 Markdown 檔案。垂直軟體公司十年累積的商業邏輯,如今可以在數週內複製完成。工作流程的護城河正在迅速消退。
3. 公開資料存取 → 商品化
垂直軟體很大一部分的價值主張,在於讓原本難以存取的資料變得容易查詢。FactSet 讓 SEC 文件可以被搜尋;LexisNexis 讓判例法可以被搜尋。這些都是真正有價值的服務。
SEC 文件在法律上確實是公開的,但試著直接用原始 HTML 去讀一份 200 頁的 10-K 就知道有多痛苦。不同公司之間的結構不一致,會計用語高度密集,而要抽取真正需要的數字,往往必須解析巢狀表格、追蹤註腳、並對重編(restated)的數據進行對帳。
在 LLM 出現之前,存取這類公開資料需要高度專用的軟體與龐大的工程基礎建設。像 FactSet 這樣的公司,為每一種申報文件、甚至每一家公司的格式差異,建立了成千上萬個解析器。隨著格式變動,還得動用大量工程師持續維護。把原始 SEC 文件轉換成可查詢資料的那套程式碼,本身就是實實在在的競爭優勢。
在 Doctrine,這同樣是大量工程投入的結果。我們為不同法域的判例建立 NLP pipeline:用命名實體辨識抽取法官、法院與法律概念;用專門的機器學習模型依法律領域分類判決;為每個法院打造客製化解析器,因為每個法院都有自己的格式怪癖。我們有工程師花了好幾年時間打造並維護這整套基礎設施。這在技術上確實非常了不起,也是真正的護城河,因為要複製它意味著多年投入。
但在 Fintool,我們什麼都沒做。沒有 NER、沒有自訂解析器、沒有任何產業專用分類模型。為什麼?因為前沿模型本來就懂。它們知道 Home Depot 的股票代號是 HD;知道 GAAP 與 non-GAAP 營收的差異;能在沒有人教結構的情況下,解析事業別揭露的巢狀表格。
Doctrine 花了好幾年打造的解析基礎設施,如今成了模型免費附帶的商品化能力。
LLM 讓這一切變得極其容易。前沿模型在訓練資料中早已學會如何解析 SEC 文件:它們理解 10-K 的結構,知道去哪裡找營收認列政策,也知道如何調和 GAAP 與 non-GAAP 的數字。你不需要再建解析器——模型本身就是解析器。把一份 10-K 丟給它,它就能回答任何相關問題;把整個聯邦判例法資料庫交給它,它就能找出相關先例。
垂直軟體花了數十年打造的「解析、結構化與查詢」能力,如今已經內建在基礎模型中,成為商品化能力。資料本身並沒有變得沒有價值;但那一層「讓資料可以被搜尋」的能力——也正是過去大量價值與定價權所在——正在迅速崩解。
4. 人才稀缺 → 被反轉
打造垂直軟體,需要同時理解產業領域與技術的人才。能夠撰寫可上線的生產級程式碼,同時又真正理解信用衍生性商品是如何結構化的工程師,極其稀有。這種稀缺性,歷史上自然形成了進入門檻,使得任何一個垂直領域中,真正有競爭力的玩家數量受到嚴格限制。
LLM 徹底顛覆了這道護城河。
在 Doctrine,招募幾乎是一場硬仗。我們不只需要好工程師,還需要能理解法律推理的工程師:判例如何運作、不同司法管轄區如何互動、向最高法院上訴的法律基礎是什麼。這樣的人幾乎不存在,所以我們只能自己培養。每週,我們都舉辦內部講座,由律師親自教工程師法律體系實際如何運作。一名新工程師往往要花上好幾個月,才能真正產生生產力。這種人才稀缺是真實存在的護城河,不只對我們如此,對任何想與我們競爭的人都是一樣。
但在 Fintool,我們完全不需要這樣做。我們的領域專家(投資組合經理、分析師)直接把自己的方法論寫進 markdown Skill 檔中。他們不需要學 Python,也不需要理解 API。他們只要用白話文字描述「一個好的 DCF 分析應該長什麼樣子」,LLM 就會負責執行。工程層由模型處理,而領域知識——那個原本一直都很充沛的資源——如今可以在沒有工程瓶頸的情況下,直接轉化為軟體。
LLM 讓工程變得極度容易取得,結果就是:原本稀缺的資源(領域專家),突然在「能被轉化為軟體」這件事上變得極度充沛。這正是為什麼進入門檻會如此劇烈地崩塌。
5. 綁定式產品組合 → 被削弱
垂直型軟體公司常透過捆綁相鄰能力來擴張。Bloomberg 一開始提供市場數據,接著加入即時通訊、新聞、分析、交易與合規工具。每新增一個模組,就提高一次轉換成本,因為客戶依賴的不再是單一產品,而是整個生態系。S&P Global 以 440 億美元收購 IHS Markit,正是這種策略的體現。捆綁本身成了護城河。
在 Doctrine,捆綁就是成長策略。我們從判例搜尋起家,接著加入法規、法律新聞、提醒通知、文件分析。每個模組都有自己的 UI、自己的新手導入流程、自己的使用情境。我們打造了複雜的儀表板,讓律師能設定追蹤清單、針對特定法律主題建立自動提醒、管理研究資料夾。每多一個功能,就意味著更多設計成本、更多工程工作、更多 UI 表面積。捆綁之所以能鎖住客戶,是因為他們已經把整個工作流程建立在我們的生態系之上。
但 LLM 代理讓功能綁定失去意義,因為代理自己就是全部的集合。在 Fintool,提醒是一個 prompt,追蹤清單是一個 prompt,投資組合篩選也是一個 prompt。沒有為每個功能獨立存在的模組,也沒有需要維護的 UI。使用者只要說:「當我投資組合中的任何公司在財報電話會議提到關稅風險時提醒我」,事情就會自動完成。Agent 會在單一工作流程中協調十多個專用工具:從某個來源拉市場數據,從另一個來源抓新聞,透過第三個跑分析,最後整理成結果。使用者既不知道、也不在乎背後其實查詢了五種不同的服務。

當整合層從軟體供應商轉移到 AI 代理時,購買整套產品的動機就此消失。既然 Agent 可以為每個能力挑選最好的(或最便宜的)供應商,為什麼還要付 Bloomberg 的高額費用,買下整個套裝?
這並不代表 bundling 會在一夕之間消失。相較於只管理一個供應商,同時協調十個供應商的營運複雜度是真實存在的。但趨勢方向已經非常清楚:AI 代理讓「去綁定」在許多過去不可能的情境下成為可行選項。
6. 私有與專有資料 → 更強
有些垂直型軟體公司擁有或授權使用那些「其他地方不存在」的資料。
Bloomberg 從全球各地的交易桌蒐集即時價格資料。S&P Global 擁有信用評等與專有分析。Dun & Bradstreet 維護超過 5 億家企業的商業信用檔案。
這些資料往往花了數十年累積,且建立在排他性的合作關係之上。你無法直接爬取,也無法重新打造。
如果你的資料真的無法被複製,那 LLM 只會讓它「更有價值」,而不是貶值。
Bloomberg 來自交易桌的即時價格資料?無法爬取、無法合成、也無法從第三方授權取得。在 LLM 的世界裡,這種資料會成為每一個 agent 都需要的稀缺投入。Bloomberg 對其專有資料的定價能力,甚至可能因此提升。
S&P Global 的信用評等也是同樣的道理。信用評等不只是資料,而是一種觀點——背後有受監管的方法論,以及數十年的違約歷史資料支撐。LLM 不能發出信用評等,S&P 可以。
判斷標準其實很簡單:這份資料能不能被其他人取得、授權,或合成?
如果不能,護城河還在;如果可以,那就麻煩了。
我在這兩家公司都親眼看過這個過程。當我們創立 Doctrine 時,核心價值是把法國的公開判例資料,透過產業化的結構重新組織:分類法、引用網路、關聯性排序。但團隊很早就意識到,單靠公開資料不夠。大約五年前,我們開始建立一個「獨家內容庫」:專有的法律註解、編輯分析、精選評論——這些內容在其他地方都不存在。今天,這個內容庫真的很難被複製,也成了真正的護城河。能撐過這次轉變的公司,都是那些從「我們把公開資料整理得比較好」,進化到「我們擁有你在任何地方都拿不到的資料」的公司。
真正改變的是這一點:過去,建立這種智慧層需要多年工程投入;現在,這幾乎是模型內建的能力。甚至連「資料存取」本身都在被商品化。MCP(Model Context Protocol)正在把每一個資料供應商變成一個外掛。已經有數十家公司把金融資料做成 MCP server,任何 AI agent 都能直接查詢。當你的資料可以直接作為 Claude 的 plugin 使用時,「讓資料變得好用」這件事本身,就不再有溢價。
諷刺的是,LLM 正在加速分化:擁有專有資料的公司,贏得更大;沒有專有資料的公司,輸掉一切。
這裡有一個令人不舒服的結論:
如果你的資料並不真正獨特——如果它能在別處被取得、授權或合成——那你並不安全。你正面臨商品化的風險。AI agent 會掌握與客戶的關係:它是使用者互動的介面、信任的品牌、付費的產品。你只會成為 agent 的供應商,而不是客戶的供應商。
這正是聚合理論(aggregation theory)的表現:聚合者(agent)掌握使用者關係與利潤,供應商(資料提供者)則為了餵養平台而彼此削價競爭。
如果 Bloomberg、FactSet,以及十多家小型供應商都提供相似的市場資料,agent 就會把請求導向最便宜的那一個。你的定價能力消失、毛利被壓縮,最終只剩下「別人產品裡的一個商品化輸入」。
7. 法規與合規所造成的鎖定 → 結構性因素
在醫療產業中,Epic 的主導地位不只是因為產品做得好,而是因為合規。HIPAA 規範、FDA 認證,以及醫院必須承受的 18 個月導入週期。更換 EHR 供應商是一個動輒好幾年、數百萬美元的專案,而且真的會影響病人安全。在金融服務業也有類似的情況:合規要求造成高度黏著性——稽核軌跡、監管申報、資料保存政策,全都已經深度內建在軟體之中。
HIPAA 不會因為有了 LLM 就改變。
FDA 認證不會因為 GPT-5 出現而變得比較容易。
SOX 的合規要求,也不會因為 Anthropic 推出新插件而鬆動。
Epic 在醫療 EHR 領域的優勢,本質上是一道監管護城河。18 個月的導入期、各種合規與認證、與醫院計費系統的深度整合——這些幾乎都不會受到 LLM 的影響。
事實上,在那些「合規鎖定最強」的垂直領域,監管要求反而可能放慢 LLM 的導入速度。醫院不可能用一個 LLM agent 直接取代 Epic,因為 LLM agent 沒有 HIPAA 認證、沒有符合要求的稽核軌跡,也沒有經過 FDA 對臨床決策支援的驗證。
8. 網路效應 → 黏著度
有些垂直型軟體,會隨著產業內使用者越多而變得越有價值。
Bloomberg 的即時通訊功能(IB chat)就是華爾街事實上的溝通層。如果你的每一個交易對手都在用 Bloomberg,你就非用不可。原因不在資料,而在網路本身。
LLM 並不會破壞網路效應。甚至可以說,它們可能讓通訊型網路變得更有價值。因為在這些網路中流動的資訊,會成為訓練資料、上下文與訊號。
這個邏輯同樣適用於任何在產業中扮演「溝通層」角色的垂直軟體。
Veeva 在製藥產業之間的網路效應,Procore 在建築產業各方利害關係人之間的網路效應。
它們之所以黏著,不是因為介面多漂亮,而是因為平台上有哪些人。價值來自網路,而不是 UI。
9. 深度嵌入交易本身 → 具備持久護城河
有些垂直型軟體直接坐落在金流之中。
餐廳的支付處理、銀行的放款起案(loan origination)、保險公司的理賠處理——當你的系統深度嵌入交易本身,切換系統就等於中斷營收。沒有人會自願這麼做。
如果你的軟體負責處理付款、發放貸款、或完成交易結算,LLM 並不會把你排除在外。它頂多成為疊在你上方的更好介面,但底層的「交易軌道」仍然不可或缺。
Stripe 不會因為 LLM 而受到威脅,FIS 也不會,Fiserv 同樣如此。
交易處理層是基礎設施,不是介面;LLM 可能改變你怎麼「使用」它,但不會讓它消失。
10. 系統紀錄地位 → 長期受威脅
當你的軟體成為關鍵商業資料的權威事實來源(canonical source of truth)時,轉換系統就不只是麻煩,而是攸關生存的風險。
如果在遷移過程中資料被破壞怎麼辦?
如果歷史紀錄遺失怎麼辦?
如果稽核軌跡斷裂怎麼辦?
Epic 是病患資料的系統紀錄來源;Salesforce 是客戶關係的系統紀錄來源。
這些公司受益於一種不對稱性:留下來的成本很高(昂貴的費用),離開的成本更高(潛在的資料流失與營運中斷)。
大型語言模型(LLMs)目前尚未直接威脅到「系統紀錄來源」的地位,但 AI agent 正在悄悄建立屬於自己的系統紀錄來源。
事情正在這樣發生:AI agent 不只是查詢既有系統。
它們會讀取你的 SharePoint、你的 Outlook、你的 Slack;它們蒐集關於使用者的資料;它們撰寫可跨 session 持續存在的詳細記憶檔案。而在執行關鍵行動時,它們會把相關脈絡一併保存下來。
久而久之,agent 累積的,會是一個比任何單一系統紀錄來源都更完整、更豐富的使用者工作全貌。
Agent 的記憶,逐漸成為新的事實來源。不是因為有人刻意設計如此,而是因為 agent 是唯一能「看到一切」的那一層。
Salesforce 只看到你的 CRM 資料。
Outlook 只看到你的電子郵件。
SharePoint 只看到你的文件。
Agent 同時看到三者,而且會記住。
這不會一夕之間發生。但從趨勢上來看,agent 正在從零開始,建立自己的系統紀錄來源,而隨著 agent 的情境記憶持續成長。
傳統系統紀錄來源的護城河,正在被一點一滴削弱。
淨效應:進入門檻崩塌
把所有因素加總起來。五個護城河被摧毀或削弱了,五個護城河仍然存在。但關鍵在於,那些被打破的護城河正是阻擋競爭者的障礙;而仍然存在的護城河,只有部分既有公司才擁有。
在大型語言模型(LLM)出現之前,要建立一個像 Bloomberg 或 LexisNexis 這樣可信的競爭產品,需要數百名熟悉該領域的工程師、數年的開發時間、龐大的資料授權合約、能夠銷售給保守企業的業務團隊,以及各種監管認證。結果是,大多數垂直領域最多只有 2-3 個真正的競爭者。
LLM 出現之後,一個小團隊只要有前沿模型 API、領域專業知識,以及良好的資料管道,就能在數月內打造出能完成垂直軟體 80% 功能的產品。我之所以知道,是因為我做過。Fintool 由六人團隊建立,我們的客戶是過去完全依賴 Bloomberg 和 FactSet 的對沖基金。原因不是我們有更好的資料,而是我們的 AI 代理能比需要多年訓練才能掌握的終端/工作站更快、更直覺地提供答案。
關鍵洞察在於,競爭並非線性增加——它是組合式爆炸的。你不會從 3 個既有玩家變成 4 個,而是從 3 個變成 300 個。這正是摧毀定價權的原因。在 LLM 出現之前,每個垂直領域都有 2-3 個主導玩家,能收取高額費用,因為進入門檻幾乎無法逾越。這個數學完全改變了:當 50 家 AI 原生的新創公司能以原價 20% 提供 80% 的能力時,市場格局完全不同。
細節分析:這是一個多年過渡,而非一夜崩塌
我認為市場在時間點上判斷錯誤,即使方向是對的。
企業收入不會一夕消失
FactSet 的客戶簽的是多年合約。Bloomberg Terminal 的合約通常至少 2 年。這些合約不會因為 Anthropic 推出一個插件就瞬間消失。
企業採購週期是以季度和年份計算的,而不是以天計算。一個 500 億美元的對沖基金不會因為 Claude 可以查詢 SEC 文件就明天就把 S&P Global CapIQ 換掉。他們會花 12–18 個月評估替代方案,進行試點計畫,談判合約條款,並等現有合約到期。
收入下滑的「懸崖」是真實存在,但它更像是一個坡,而不是懸崖。現有收入在未來 12–24 個月基本上是鎖定的。
但事情是這樣的,市場已經理解:你不需要收入下滑,股價也可能崩跌。你只需要「倍數收縮」。一間財經數據公司,當它擁有定價權且客戶留存率 95% 時,可能以 15 倍收入交易;但當市場認為這些護城河正在消失,它可能只值 6 倍收入。收入保持平穩,股價卻下跌 60%。這正是目前部分公司的情況。
市場不是在預期收入崩塌,而是在預期「高價倍數的結束」,因為支撐這個倍數的護城河正在消失。
真正的威脅
真正的威脅不是大型語言模型(LLM)本身,而是一個縱橫夾擊,傳統垂直軟體公司沒料到的局面。
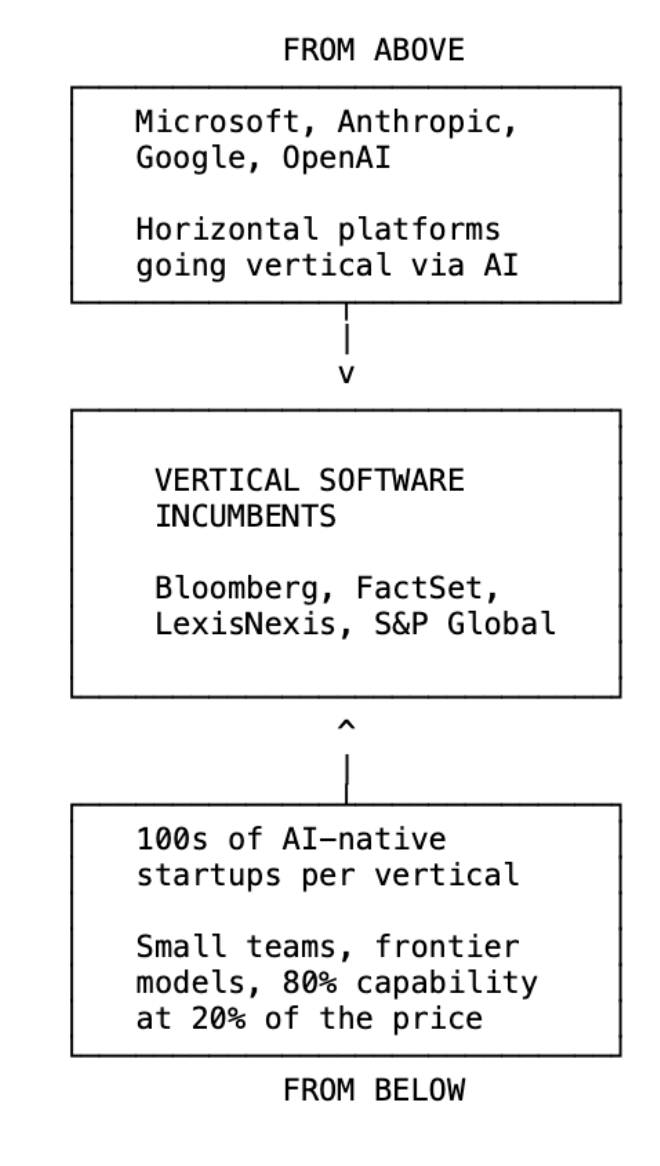
從下方來看,數百家 AI 原生的新創公司正在進入各個垂直領域。過去,要建立一個可信的金融數據產品,需要 200 位工程師和 5000 萬美元的數據授權費,市場自然集中在 3–4 家玩家手中。但當只需要 10 位工程師和最前沿的模型 API,市場就會劇烈分散。競爭從 3 家變成 300 家。
從上方來看,水平平台首次深入垂直領域。Microsoft Copilot 在 Excel 中已經能做 AI 驅動的 DCF 模型與財務報表解析;在 Word 中則能進行合約審查與案例法研究。水平工具透過 AI 變成垂直工具,而不是靠工程規模。
Anthropic 正從另一個方向做同樣的事。我特別關注,因為 Fintool 是 Anthropic 支持的公司。Claude 正全面進攻垂直領域,其操作手冊極其簡單:通用代理工具(SDK)、可插拔的數據存取(MCP)、以及特定領域 Skill(Markdown 文件)。就這些,這整個堆疊就足以把水平平台轉成垂直平台。無需領域工程師,無需多年開發。
軟體正在變得「無頭化」。介面消失,一切都透過代理流動。重要的已不再是軟體本身,而是掌握客戶關係與使用場景,也就是掌握代理本身。
能夠實現垂直深度的技術(LLM + skills + MCP),同時也是讓水平平台能夠進入以往無法觸及領域的技術。這也許是對垂直軟體最具生存威脅的地方:像 Microsoft 這樣的水平 B2B 玩家已經不再只是涉獵垂直領域,而是積極擴張,因為現在比以往任何時候都容易做到,而且他們必須掌握使用場景與工作流程,才能在 AI 為先的世界中保持競爭力。
風險評估框架
並非所有垂直型軟體面臨的風險都一樣。以下是我用來判斷哪些類別能存活、哪些可能出局的思考方式。
高風險:搜尋層(Search Layer)
如果你的核心價值在於,透過一個專門化的介面,讓資料更容易被搜尋與存取,而底層資料本身是公開的或可授權取得的,那你正身處險境。這包括:建立在授權交易所資料上的金融資料終端、建立在公開判例法上的法律研究平台、專利搜尋工具,以及任何本質上等於「我們為你這個產業做了一個更好的搜尋引擎」的產品。
這類公司過去能以 15–20 倍營收估值交易,靠的是介面鎖定效應與有限競爭。但這兩者正在迅速蒸發。看看那些在過去一年市值下跌 40–60% 的金融資料供應商,市場重新定價是合理的。
中度風險:混合型投資組合
許多垂直軟體公司同時擁有具防禦性與高度曝險的業務線。一家公司可能一方面有真正專有的評級業務,另一方面卻有主要只是重新包裝公開資訊的資料分析部門;或者同時擁有指數授權業務(嵌入交易流程中、極具防禦性)與研究平台(純搜尋層、高度曝險)。
這一類公司股價下跌 20–30%,反映的是市場對於「究竟哪個部門主導整體估值」的不確定性。關鍵問題在於:有多少營收來自 LLM 無法觸及的護城河?
較低風險:法規堡壘
如果你的護城河來自法規認證、合規基礎設施,以及與關鍵任務工作流程的深度整合,那在中期內,LLM 幾乎不會動搖你的競爭地位。像是具備 HIPAA 合規與 FDA 驗證的醫療 EHR 系統、有法規鎖定效應的生命科學平台、金融合規與申報基礎設施。
這些公司甚至可能因其他領域的 AI 顛覆而受益,因為客戶會在受管制的工作流程上,集中選擇他們信任的供應商,同時捨棄僅用於資訊檢索的工具型廠商。
檢驗方式
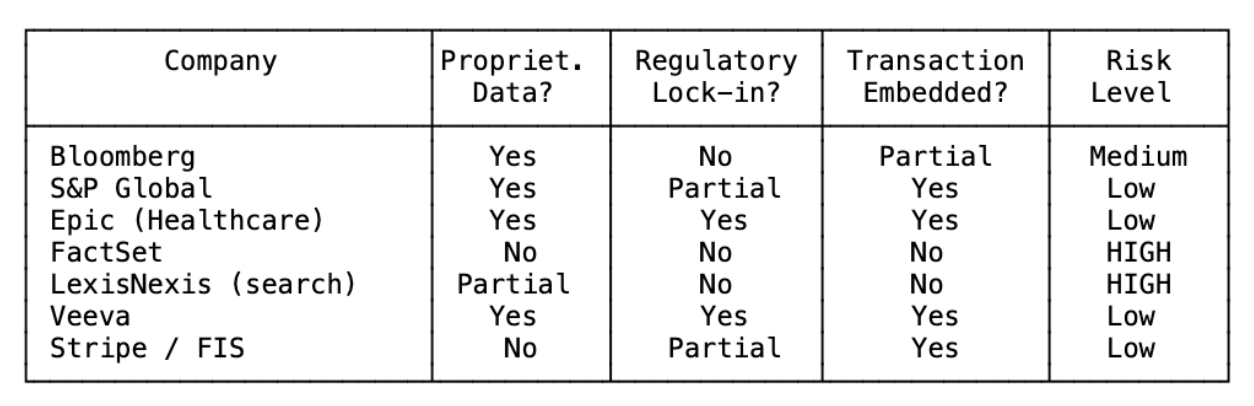
對任何一家垂直軟體公司,問三個問題:
- 資料是否為專有?如果是,護城河仍在;如果不是,存取層正在崩解。
- 是否存在法規鎖定?如果是,LLM 不會改變轉換成本;如果不是,轉換成本主要來自介面,且正在消散。
- 軟體是否嵌入在交易流程中?如果是,LLM 只會疊加在你之上,而非取代你;如果不是,你是可被替換的。
零個「是」:高風險。一個:中度風險。兩個或三個:大致安全。
我在兩種極端產品開發中的心得
當我從 2016 年開始建立 Doctrine 時,其中一個護城河是介面。我們打造了漂亮的案例法搜尋體驗,律師們很喜歡,因為比市面上任何產品都更快速、更直覺。大部分資料是公開的,但我們的介面和搜尋方式讓資料變得易於存取。如果今天我要從零開始重建 Doctrine,這個業務將面臨根本不同的競爭環境。LLM 代理能像我們的介面一樣有效地查詢案例法。
這個體悟正是我建立 Fintool 的原因不同。我們不靠介面競爭,而是靠 AI 代理的輸出品質、我們建構的專屬技能與數據管線,以及我們與專業投資人建立的信任——這些投資人依賴我們的準確度做出百萬美元的決策。當介面變成對話時,產品本身就是其背後的智慧。
垂直 SaaS 的洗牌,不是說所有垂直軟體都會消失,而是市場終於開始分辨:哪些公司擁有真正稀缺的資源,哪些只是把別人的資料包裝成漂亮的介面。
Dr. J
喜歡這篇文章嗎?
訂閱電子報,不錯過最新內容!